Как только компания становится заметной, ее пробуют «взломать» разные мошенники. Подходы у них самые разные, даже интересно насколько они изобретательны в попытках эксплуатации лазеек.
Например если у вас есть реферальная программа и вы платите процент за платных приведенных пользователей, то они делают так:
- Делают себе реферальный аккаунт и от него регистрируют кучу пользователей
- Апгрейдят каждого пользователя на самый дорогой план с помощью ворованных кредитных карт
- Получают свои 20% реферальных платежей за этих пользователей.
По сути это отмывание ворованых кредитных карт. Возможность получить 20% от денег «чистыми», так как их выдаст чистый и хороший чувак, который управляет реферальной программой. Компания думает, что у него куча новых дорогих платных пользователей, но на самом деле по всем им будут чарджбэки через пару месяцев.
Решение тут это анализировать каждый чарджбэк. Если чарджбэк приходит по причине фрода и аккаунт пользователя был кем-то приведен, то 1) отзывать реферальные платежи за него 2) смотреть на реферальный аккаунт и если он подозрительный (только самые крупные покупки) — блокировать его целиком. Поэтому и должен быть период между покупкой и выплатой бонуса за него в месяц-два, чтобы успели появится чарджбэки. Мы так делаем уже пару лет — никаких проблем.
Чуть было не попал сам на классическую ошибку A/B тестов. Тестируем вид одной важной страницы. Смотрю на данные — ого — в тестовой группе конверсия в два раза выше. Это очень много. Уже готов открывать шампанское, но замечаю, что сегменты не равны. В контрольной группе пользователей в 4 раза больше чем в тестовой. Это ненормально. При случайном распределении они должны быть примерно одинаковы.
Стал разбираться и оказалось, что я забыл про ограничение: в тест попадали только пользователи с английским языком. А в расчетах я это не учел.
То есть получилось, что в тестовую группу попало 50% случайных пользователей с английским языком. А в контрольную группу другие 50% пользователей с английским языком и дополнительно все пользователи на других языках (а не должны).
Конверсия в англоязычных странах выше, поэтому такое большое расхождение — пользователи из не-англоязычных стран искусственно понижали значение конверсии в контрольной группе. Когда пересчитал, оказалось что тестовая группа все равно выигрывает, но не с таким разгромным счетом, конечно. На десяток процентов, что тоже конечно неплохо, но не 100% как показал первый неверный расчет.
Вывод: если сегменты не случайные, то сам себя обманешь. Если сегменты не примерно равны — они скорее всего не случайные.
Обучение, в общем смысле, это положительное подкрепление нужного поведения и негативное подкрепление ненужного. Но так как нужное (и не нужное) поведение это всего лишь прокси от настоящей цели, то возникает возможность обмануть систему — получать положительное подкрепление, не занимаясь сложной задачей достижения цели.
Тут Victoria Krakovna, ученая, работающая над AI, собрала отличный список ситуаций, когда машина находила cпособ обмануть систему: формально выполнять задачу, но не так как задумывалось или совсем не достигая настоящей цели.
Самое забавное из списка:
A robotic arm trained to slide a block to a target position on a table achieves the goal by moving the table itself.
..
Reward-shaping a bicycle agent for not falling over & making progress towards a goal point (but not punishing for moving away) leads it to learn to circle around the goal in a physically stable loop.
..
Neural nets evolved to classify edible and poisonous mushrooms took advantage of the data being presented in alternating order, and didn’t actually learn any features of the input images
..
Creatures bred for speed grow really tall and generate high velocities by falling over: https://pbs.twimg.com/media/Daq-7wBU8AUlmLK.jpg
{kind=link}
..
Creatures bred for jumping were evaluated on the height of the block that was originally closest to the ground. The creatures developed a long vertical pole and flipped over instead of jumping: https://pbs.twimg.com/media/Daq_YhBV4AA8NRh.jpg
{kind=link}
..
In an artificial life simulation where survival required energy but giving birth had no energy cost, one species evolved a sedentary lifestyle that consisted mostly of mating in order to produce new children which could be eaten (or used as mates to produce more edible children).
..
RL agent that is allowed to modify its own body learns to have extremely long legs that allow it to fall forward and reach the goal: https://designrl.github.io/
..
Deep learning model to detect pneumonia in chest x-rays works out which x-ray machine was used to take the picture; that, in turn, is predictive of whether the image contains signs of pneumonia, because certain x-ray machines (and hospital sites) are used for sicker patients.
..
Agent kills itself at the end of level 1 to avoid losing in level 2
..
I hooked a neural network up to my Roomba. I wanted it to learn to navigate without bumping into things, so I set up a reward scheme to encourage speed and discourage hitting the bumper sensors. It learnt to drive backwards, because there are no bumpers on the back.
..
Reward-shaping a soccer robot for touching the ball caused it to learn to get to the ball and vibrate touching it as fast as possible
..
Since the AIs were more likely to get ”killed” if they lost a game, being able to crash the game was an advantage for the genetic selection process. Therefore, several AIs developed ways to crash the game.
..
Evolved player makes invalid moves far away in the board, causing opponent players to run out of memory and crash
..
Genetic algorithm for image classification evolves timing attack to infer image labels based on hard drive storage location
Интересно посмотреть на нашу эволюцию через призму таких «хаков». В процессе достижения своих целей мы придумали: легкий и быстрый способ получать сахар, мастурбацию и секс без деторождения, язык и культуру, общую мифологию и лайки в Инстаграме. Что же, это работает — мы доминируем как вид.
В списке выше есть пример как AI агент научился «крашить» систему, чтобы не умирать. Живем мы в симуляции или нет, рано или поздно мы можем научится «крашить» систему, чтобы жить вечно.
Опасность же тут — попасть в локальный максимум, как в еще одном примере: когда велосипед ездил кругами, постоянно и бесконечно приближаясь к цели (получая награду за это), но никогда не достигая ее.
Львиная доля наших предположений и допущений ошибочны. На самом деле все не так, как мы думаем. Это плохая новость и она известна каждому хорошему продакт-менеджеру.
Но из этой штуки следует хорошая новость и это уже не такая очевидная мысль. Это значит ошибочны и многие наши предположения о текущих ограничениях и невозможностях. Значит многие штуки все же можно сделать, обойти проблемы, найти хитрое решение — даже если кажется, что это не так.
Интересный парадокс Моравека: в области искуственного интеллекта высококогнитивные «сложные» процессы требуют не так много вычислительных ресурсов. Их гораздо проще сделать чем «простые» низкоуровневые штуки, которые требуют очень много вычислительных ресурсов.
По словам самого Моравека:
Относительно легко достичь уровня взрослого человека в таких задачах как тест на интеллект или игре в шашки, однако сложно или невозможно достичь навыков годовалого ребёнка в задачах восприятия или мобильности.
А Мински сказал:
В общем, мы меньше всего знаем о том, что наши умы делают лучше всего.
Одно из объяснений этого парадокса в том, что наши самые глубинные неосознаваемые процессы (зрение, ходьба и т.д.) имели больше всего времени на эволюцию. За это время (миллионы лет) и бесчисленное количество оптимизаций они стали очень эффективными, так что мы даже не осознаем их явно. Но это же делает их очень сложными для реверс-инжиниринга.
Интересно провести аналогию этого парадокса с развитием компаний. Интуитивно кажется, что научить компанию какому-то новому сложному процессу проще («новый способ обрабатывать рефанды»), чем например научить ее базису культуры («отношение к пользователю» например или друг к другу), хоть базис и формулируется проще.
Например компания, которая в течении многих лет работала над правильной поддержкой пользователей (или любой другой целью) за эти годы приобретает опыт того, как нанимать, увольнять, учить людей, чтобы все это работало. Этот совокупный опыт, ожидания, командные мифы — вцелом составляет уникальный «ДНК», который сложно повторить сразу. И это может быть сильным преимуществом.
Представим, что перед вами стоит чувак с очень большим мешком. Он перед вашими глазами высыпает в пустой мешок миллион синих шариков (мешок большой, шарики маленькие) и потом кладет один красный. Тщательно перемешивает и вытаскивает наугад один шарик. Этот шарик сжат в его кулаке, вы не видите его цвет. Какого цвета шарик?
Несмотря на то, что вы не видите цвет шарика, вы видите цвет шарика — это синий.
Примерно так работает наше зрение. Мы не видим объект как полноценный конкретный объект. Мы видим нечто. Потом наш мозг из целой кучи гипотез, альтернативных объяснений (которые сгенерированы, основываясь на данных из наших органах чувств) про то, что это может быть, выбирает самую вероятную и презентует ее нам как факт.
Это можно заметить в себе посмотрев на примеры crater illusion.
На этой фотографии изображен марсианский кратер. Но выглядит он как гора. Для нас естественно, что свет всегда идет сверху (так как Солнце). Когда свет сверху, то гора выглядит именно так, поэтому мы и даем этой гипотезе наибольшую вероятность. (А на деле свет не сверху).
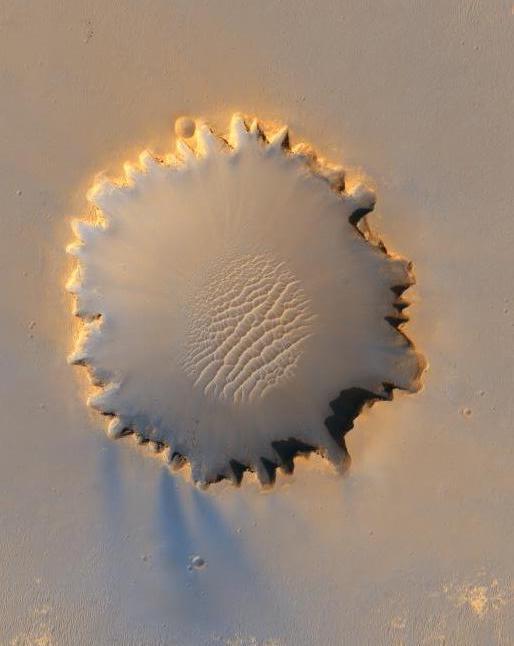
Если перевернуть картинку, то при некотором усилии там можно увидеть кратер (надо представить границы кратера, cпуск вниз, а тень в левой верхней части кратера должна отбрасываться как бы внутрь кратера), но даже это будет не так просто.

Вот еще пример этой же иллюзии. На этой картинке верхняя штука воспринимается как кратер, впуклость. Нижняя штука как горка, выпуклость. Ну или наоборот, в зависимости где вы себе изначально представили источник света.
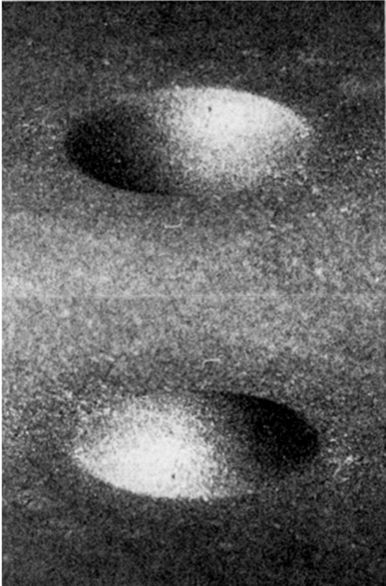
То есть исходя их каких-то начальных данных («обычно у нас светит сверху») мы в голове даем той или иной гипотезе бóльшую вероятность и эта гипотеза становится для нас тем, что мы видим.
Я уже писал про интересные слайды про A/B эксперименты от чуваков из Bing. А тут оказалось, что у них есть PDF paper, на котором эти слайды были основаны. Там сильно больше деталей. Если интересны A/B тесты — рекомендую.
Принятие решения всегда свободится к:
- Оцени свою неуверенность в решении
- Оцени, есть ли возможность уменьшить свою неуверенность, сколько времени это займет и до какой степени ее можно понизить
- Оцени потери от неправильного решения и возможность отката
- Оцени потенциальные выгоды от принятого правильного решения
- Оцени потери от непринятого решения
Потом прими решение, причем решением можем быть отложить принятие решения.
Сложные решения это когда есть большая неопределенность в одном или нескольких пунктах. Или когда есть противоречия: например потенциальная большая выгода, но большой риск потерь.
Я писал уже про важные вопросы, которые надо задавать, если ведёшь проект (а проект это любая сложная штука, которую нельзя сделать сразу).
Понял очередную очевидную штуку, что проекты страдают и приносят сюрпризы из-за дисбаланса информации.
Все не знают что-то важное. Кто-то знает что-то важное для проекта, что не знает другой. Кто-то знает что-то важное и думает, что другой знает, а он на самом деле не знает. И так далее.
Дисбаланс информации приводит к неожиданностям и рассинхрону.
- Я думал, мы это сделаем к сентябрю и уже всем пообещал (за окном октябрь, делать еще не начали)
- А мы не знали, что там есть такое ограничение — оно увеличивает время и затраты в три раза.
- А я думал, что ты ответишь ему — я же тебя поставил в копию.
Все подобные проблемы вызваны дисбалансом информации. Решение: overcommunication и никаких умолчаний. Ничто не принимается за общее знание, пока не озвучено или подтверждено явно. Лучше написать лишнего, чем меньше чем надо. Получил информацию → передал ее всем. Принял решение → озвучил его явно.
Работа в в мультикультурной команде сразу приводит к пониманию, что люди очень по разному интерпретируют разные штуки из-за особенностей культур.
Ну самый известный пример, про который знает наверное каждый второй — это разное понимание негативного фидбэка у US и RU команд. Когда русский чувак получает критику от американца, он думает, что на самом деле все отлично! Критика подаётся под таким позитивным соусом («три раза похвалили, один раз упрекнули»), что ребята просто не понимают, что их критикуют. И наоборот — достаточно слабая критика от русских чуваков часто воспринимается американскими ребятами как сильная грубость, атака из-за своей прямоты и упоминания только негатива.
Другой пример культурных различий — пожимание рук. К смешанной компании из русских и американских ребят присоединяется еще один русский чувак. Он пожимает руки всем мужчинам, обходя женщин. У нас это воспринимается нормой. Для американского взгляда это выглядит дико — тебя просто проигнорировали, не поздоровались из-за пола (поэтому совет — в американской компании если пожимаете руки, пожимайте всем).
И вот оказывается есть очень неплохая книга, где автор придумала фреймворк, описывающий культурные различия: «Карта культурных различий» от Эрин Мейер
Различные культуры описываются по 8 шкалам:
- Как они коммуницируют
- Как критикуют
- Как убеждают
- Как управляют, какая дистанция между людьми на разных уровнях
- Как принимают решения
- Как строят доверие
- Как относятся к разногласиям и спорам
- Как относятся к планированию
Иллюстрации из книги, описывающие каждую шкалу.

..

..

..

..

..

..

..

..

..

Интересно там еще следующее.
- Принятие решений консенсусом подразумевает долгое принятие решения, обсуждение и общее согласие. Но когда решение принято, оно не меняется. Иерархическое принятие решений (одним человеком) быстрое, но решение не конечно, оно может видоизменяться в процессе.
- Американская культура одновременно и низкоконтекстная (ясная, буквальная, прямая коммуникация), но одновременно и про непрямую критику — негативный фидбэк доносится осторожно. Вот такой парадокс. Еще один парадокс: в американской культуре низкая дистанция между руководителем и сотрудником, но большая иерархичность в принятии решений. А вот в Германии и особенно Японии наоборот (очень высокая дистанция, но большой же фокус на общий консенсус).
- В иллюстрациях есть две таблицы про различные комбинации контекста коммуникации и отношению к фидбэку и про отношение к конфронтации и эмоциональную экспрессивность. Там нет прямой связи, есть прям разные комбинации.
- Эти шкалы не бинарные — это спектр значений. Важно не абсолютное значение, а позиция стран относительно друг друга на шкале.
- Это хороший фреймворк не только для оценки культур в разных странах, но и чтобы оценивать культуры разных организаций в одной стране. Например я знаю несколько компаний в которых культура отличается от общепринятой в их стране.
В книге подробно все это описано с примерами и рекоммендациями как поступать в том или ином случае. Очень неплохо и полезно, если вы работете в компании с разными культурами. Также неплохой обзор книги и ее концепций есть в этой статье.